


May 11, 2015
If you ever wanted to create an application that can compare information from other websites, you can do so by implementing code that uses web scraping.
To achieve this, you can use one of the NuGet packages called "HTMLAgilityPack." This will allow you to retrieve the data in mind and is sometimes called scraping. You must also ensure that the sites you want to get information from allows you to use this method on their site by reading the terms of usage.
In my example, I will use a form with a WebBrowser control, to display the website and a button that will issue the scraping to start.
Once you have the package installed, you can reference the library by adding the namespace to the needed class. It will be to your benefit to add the XML namespaces to so you can accurately retrieve the needed elements.

Once you have that referenced, you can make sure your WebBrowser control displays the correct site by adjusting the URL property.
First, when you want to use scraping, you have to give your application a htmlDocument to work with. This document will represent the website you are retrieving information from.

After you passed in the document to be used, work out the absolute path to the HTML element that you want to work with and save it in a string value. This path will be used by our application to extract the information we want. If you have worked with Google chrome and its element inspector tool, you can right click the element and click on Copy Xpath.
 Once you have the element you are looking for, you can then start working with the element. As we are working with a table, we must set our code up to use iteration on it. To do this, we create a NodeCollection object.
Once you have the element you are looking for, you can then start working with the element. As we are working with a table, we must set our code up to use iteration on it. To do this, we create a NodeCollection object.
Once we have the collection populated, we can form a loop to iterate through the collection and grab each individual record. In the next piece of code, I represent the loop statement with full logic.
The loop condition is set to the number of items in the collection so we iterate through all of them. We then create an HtmlNode object to represent each row in the collection.
Inside of our table row we have td elements, so once again we set an Xpath string to the specific element in mind. This is td because we want the information from the columns. In my case, I have 5 columns so I create an HtmlNode array with a size of 5, to represent the value of each column.
Then create a collection to represent each of the columns in a table row, these can be retrieved by using the ChildNodes property on the HtmlNode object called TR (the one representing the table row), and using the index number of each column. By using this index number the first column will be number 0.
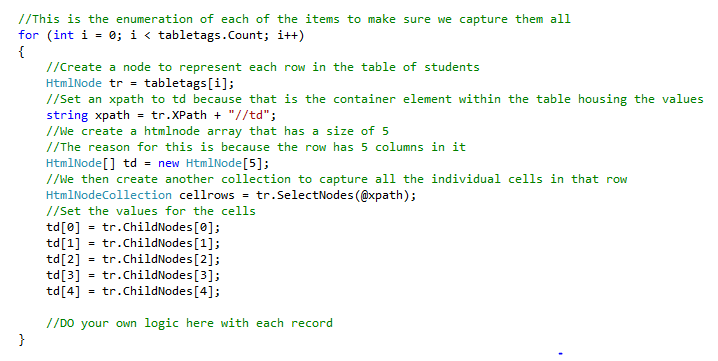
Once you have these fields captured, you can decide what you want to do with the individual fields.
How do your Excel skills stack up?
Test NowRelated Articles







About the Author:
Auret Swanepoel

As a recent addition to the New Horizons team, Auret is a highly skilled and qualified IT Technical trainer. He has been a Microsoft Certified Trainer (MCT) since 2008 and has since then, also become a Microsoft Certified Professional (MCP), a Microsoft Certified Technology Specialist (MCTS) and a Microsoft Certified Information Technology Professional (MCITP). With his international experience as a trainer in South Africa, Auret is able to adapt his teaching style to different audiences in the classroom and ensure that students are learning in a positive and collaborative environment.
Read full bio

Next up:
- How to create an e-mail template in Outlook
- How to avoid reinventing the wheel
- Quick ways to automate in Photoshop – Part 2: Modifying an Action
- What is new in Office 365
- Find a filter result without filtering in Excel
- Managing application settings in Windows Store Apps
- The art of thinking clearly
- Remove those rogue records in Excel
- New Hyper-V cmdlets in PowerShell 4.0
- Understanding the difference between Office 2013 and Office 365
Previously
- Round, RoundUp and RoundDown in Excel
- Have you ever...?
- Different communication styles, Part 1 - the best communicators know this, so should you.
- Group data in ranges of values in Excel
- Create a Windows 8.1 Enterprise Reference Image with MDT 2013
- Are You a Smarter Buyer?
- Installing ClockworkWorkMod recovery on your Samsung device
- Termination is possible
- Outlook rules rule!
- Group Managed Service Accounts in Windows Server 2012
